In the realm of contemporary education, the integration of advanced technology is not just a trend but a necessity. ”EDSense” emerges as a cutting-edge platform at the intersection of educational needs and technological innovation. This paper focuses on the development of a social educational platform, leveraging artificial intelligence (AI) uniquely designed to support the official educational curriculum, catering to a wide range of users from students and teachers in grades I-XII in Romania, to adult learners. Central to EDSense is the use of AI for personalized learning experiences. This includes the implementation of sophisticated recommending systems that adapt to individual learning styles and progress. Personalized quizzes, crafted using AI algorithms, offer a tailored approach to assess and reinforce learning. Furthermore, EDSense employs sentiment analysis to gauge and respond to the emotional and cognitive states of learners, thereby enhancing the overall learning experience. The platform stands as a testament to the potential of AI in revolutionizing education. By combining educational content with state-of-the-art technology, EDSense aims to provide an engaging, effective, and highly personalized learning journey, setting a new standard in educational technology.
____________________
Journal of Digital Pedagogy – ISSN 3008 – 2021
2023, Vol. 2, No. 1, pp. 14-24
https://doi.org/10.61071/JDP.2375
HTML | PDF
____________________
1. Introduction
The main objective of this work is the applied research and technological development of an educational social platform based on artificial intelligence technologies, designed for learning and disseminating specific educational knowledge as outlined in official school programs. The EDSENSE platform is intended for both students and teachers from grades I-XII in Romania, as well as for adults (e.g., parents) interested in the educational process. Therefore, the development of the proposed technological platform involved the design of a large-scale intelligent distributed system that will incorporate: high-quality educational content created in collaboration with recognized educators for the quality of the educational process, and intelligent subsystems for recommendation, content search, personalized questionnaire creation or learning plans, user communication, as well as sentiment analysis based on posted comments. These subsystems will provide the possibility of creating a personalized/ adaptive context.
The motivation for developing such a platform stems from the fact that current e-learning platforms do not simultaneously address aspects such as: a) knowledge being transmitted by both teachers and students; b) posts, searches, comments, and intellectual involvement being easily achieved; c) artificial intelligence modules supporting each user with relevant material, aiding them in the learning process; d) stimulating creativity, involvement, and the ability to formulate opinions complementary to those presented by tutors; e) incorporating a wide range of AI and Machine Learning modules covering various situations, from personal AI assistance to exploratory data analysis (EDA); e) supporting learning through the implementation of a large-scale collaborative paradigm; f) integrating a variety of software technologies such as web, artificial intelligence, mobile applications, augmented reality, social networks, gamification, machine learning, and statistics.
It is important for modern educational platforms to be able to develop large digital communities centred around specific educational content derived from the official curriculum, with various levels of granularity (e.g., a subject, a chapter, a concept). Thus, a digital community will consist of all users who follow a particular element and actively contribute to its development through comments, likes, and communication with other users within the respective topic. From the perspective of artificial intelligence technologies, the design and development of the EDSense platform architecture were based on specific architectural elements, including:
- The EDSense technology platform is built around the synergy of the latest artificial intelligence techniques: deep learning, recommendation systems, content filtering systems, and intelligent search engines;
- The ‘Intelligent Digital Page’ represents a central architectural element of the EDSense platform, enabling content personalization, aggregation of informational components, content provided by artificial intelligence subsystems, and the communication subsystem;
- The EDSense platform contains uses artificial intelligence modules to learn about users’ characteristics, competencies/ skills, and individually assists them throughout the learning process, offering personalized content based on their interests and activities within specific educational areas;
- The EDSense platform will include an intelligent module for automatic refinement of user-posted comments (identifying inappropriate text content);
- The platform features an efficient/ probabilistic intelligence-based item knowledge search engine;
- The EDSense platform contains an innovative module based on modern data exploration and analysis techniques (machine learning), which will provide relevant knowledge about user engagement in different categories (classes, subjects).
In summary, the EDSense platform aims to complementarily contribute to the support/ improvement of educational processes in the traditional educational system, promoting a new, modern approach supported by cutting-edge intelligent technologies. Formally, students can become sources of knowledge with dissemination potential. Within a distributed knowledge system, students can represent active nodes in the dissemination of knowledge, enhancing the entire system as a whole.
2. Literature Review
The integration of artificial intelligence (AI) in educational e-learning platforms has the potential to revolutionize the way people learn. Current strategies for enhancing e-learning platforms have already incorporated AI to improve user experience, facilitate more effective learning, and offer personalized recommendations. In order to keep up with the ever-evolving educational landscape, e-learning systems need to be adapted to meet the needs of both teachers and students (M. Liu & Yu, 2023). This requires new pedagogical approaches and cognitive strategies to ensure the efficient transmission and delivery of learning resources (M. Liu & Yu, 2023). Additionally, without proper supervision and guidance, unmotivated learners may fall behind. Furthermore, users can choose components to meet their needs for teaching and learning, and e-learning platforms can be an integration of related components that support instructional or learning models (Gao et al., 2021). The available technologies to generate novel and exciting courses are continually changing, and course content should be promptly updated to provide students with the most current information (Omar et al., 2011).
Artificial intelligence (AI) can be used to improve e-learning platforms in various ways. AI can be used in e-learning platforms through adaptive hypermedia information retrieval systems, adaptive annotation systems, adaptive recommendation systems, adaptive web navigation, and adaptive feedback (Gros & García-Peñalvo, 2016). AI algorithms can be used to evaluate students’ current learning conditions using online tests, and provide adapted modules to identify their learning gap (M. Liu & Yu, 2023). Adaptive learning or personalized learning aims to tailor the massive information available to learners based on their features, preferences, background, and learning behaviours (Zhang & Aslan, 2021). AI can assist students by providing personalized study materials and offering feedback based on their strengths and weaknesses (Murtaza et al., 2022). AI can also be used to monitor or assess student progress, and alert teachers if there are any problems with student performance (M. Liu & Yu, 2023).
The current strategies of e-learning are being constantly upgraded with the help of emerging technologies (Gros & García-Peñalvo, 2016). As a result, the use of AI in e-learning is on the rise, as AI can provide personalized learning [2]. AI-driven e-learning platforms are good for students as they can access the same content from the comfort of their home (Saleh, 2022), and AI-driven platforms can deliver personalized content (Collins et al., 2003). The use of AI in e-learning can also provide a better understanding of learners’ needs and allow for more customized learning strategies. For instance, AI-driven platforms can address cheating during e-learning (Omar et al., 2011) and provide better learning conditions during pandemics (Tang et al., 2023). Additionally, AI can facilitate personalization and customization of the learning process (Montebello, 2014), by providing personalized course material and feedback to learners based on their characteristics (Luan et al., 2020). AI can also enable the creation of intelligent tutoring systems (Eryılmaz et al., 2019), improve the quality of electronic information talents in the mobile network industry, and provide good hardware portability for e-learning platforms through the use of edge computing (Gao et al., 2021).
With the emergence of artificial intelligence (AI) technologies, online learning environments have become more adaptive and sophisticated. AI-driven adaptive learning solutions are rapidly being implemented to improve the user experience and increase the efficiency of learning (Chiu et al., 2023). For instance, AI can be used to construct adaptive hypermedia information retrieval systems, adaptive annotation systems, adaptive recommendation systems, adaptive web navigation, and adaptive feedback. Adaptive learning utilizes a data-driven approach to identify students’ needs faster and enable the delivery of personalized learning at scale (Dogan et al., 2023).
3. Results and Discussion
The implementation of the EDSense educational platform is based on the development of a modular technological architecture grounded in a suite of modern technologies (web development frameworks, recommendation systems, content filtering systems, search systems, sentiment analysis systems, computer graphics, gamification, scalable data structures, etc.).
The EDSense educational platform integrates collections of personalized DSPs (Digital Smart Pages) that are utilizing elements of gamification and augmented reality. These intelligent pages are composed of four categories of components (Manual, Multimedia, Benchmark, Collaborative Intelligent Learning), components that are consuming data stored in specialized data repositories and that are using the algorithms implemented in five intelligent modules: a) search engine, b) recommendation system, c) sentiment analysis module, d) personalized questionnaire generation system, e) user communication system). These modules, which makes the platform an intelligent one, are to be further presented.
Smart Component I, the ‘EDSense Intelligent Search Engine,’ has the primary objective of providing relevant links for various user-initiated searches. The problem of retrieving stored data (information) is not a trivial one, as it is a challenging issue, especially in a way that can satisfy all users, from novices (who desire a simplified system) to specialists (who require precise and extensive searches). Given that data is managed through file systems, the solution was to overlay a retrieval system (expert information retrieval system) – as shown in Figure 1 – that would provide the possibility of searching based on various criteria.
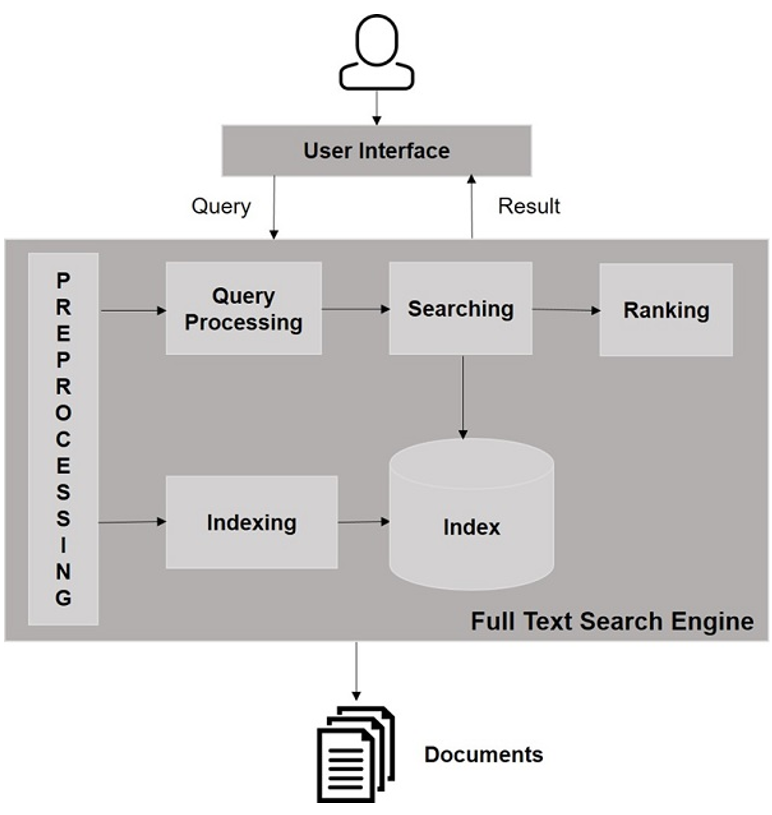
The basic idea was that the user comes with a request to search for information, and the platform must provide results as close as possible to the user’s requirements. Therefore, the focus in implementing such a system should be on two elements:
- Extracting search criteria from the user’s request (at a higher level, the user can specify the type of search in a as natural language as possible);
- Actually storing and retrieving meta-information (information about documents) that allows for finding (preferably quickly) documents based on specified parameters.
Regarding the extraction of criteria, this can be done through various technologies such as artificial intelligence or specialized text parsers. However, what needs to be obtained as a result of this stage should be a formalized request in an explicit format that can be taken over by the second component of the system. This second component has the role of storing meta-information and effectively retrieving it. The storage/ modification of the structures used to store information must be closely related to the file system (when creating/ modifying/ deleting a document, changes must also be made in the retrieval system). As for the implementation of the search system, ElasticSearch-type database servers were used to store the structures used for storage in the form of tables in a database with structures determined by predefined ontologies. To avoid data redundancy, each physical document could have attached within the retrieval system a record with the meta-information of the structures containing the sought information.
Smart Component II, the ‘Educational Content Recommendation Module based on User History,’ provides EDSense users with personalized recommendations in the form of ordered lists of articles. The recommendation system attempts to predict the most suitable knowledge products for students using user preferences and certain constraints. To accomplish this task, the system collects user preferences, which can either be explicitly expressed (e.g., ratings) or inferred from their actions (e.g., navigating to a specific page might be interpreted as an implicit preference for the items on that page). Recommendation systems emerged as an independent research field in the mid-1990s (Isinkaye et al., 2015), becoming a significant subset of information filtering systems. These systems are tools and techniques that provide suggestions for articles to be presented to users (Rivera et al., 2018). The term “article” is the general term used to refer to what the system recommends to users. Articles can be characterized by their complexity, value, or utility. The value of an article can be positive if it is valuable to the user or negative if it doesn’t align with the user’s preferences, indicating that the user made an incorrect choice in selecting the article. A recommendation system typically focuses on a specific type of product, and as a result, its design, user interface, and fundamental recommendation technique are tailored to provide useful and effective suggestions for that specific type of product. Recommendation systems have proven to be valuable means of coping with information overload in recent years. Ultimately, a recommendation system addresses this phenomenon by suggesting new articles to a user that haven’t been experienced yet and may be relevant to the current task. Upon a user’s request, depending on the recommendation technique, context, and user needs, the system generates recommendations using various types of user information and data (available items and previous transactions stored in a database). Subsequently, the user can navigate through the recommendations, allowing them to provide immediate or subsequent implicit or explicit feedback. All these user actions can be stored and used later to generate new recommendations in subsequent interactions. There are several advantages for EDSense users from the perspective of a recommendation system: a) Increased User Satisfaction: A well-designed recommendation system can enhance the user experience with the website or application. Users will find the recommendations interesting, relevant, and presented in a user-friendly design. The combination of efficiency, accuracy, recommendations, and an easy-to-use interface will increase the system’s usage and the likelihood of users accepting the recommendations; b) Better Understanding of User Needs: Another important function of recommendation systems, which can be extended to many applications, is describing user preferences, whether collected explicitly or predicted by the system. The service provider can then reuse this knowledge for various purposes; c) Increased User Loyalty: A user should be loyal to the educational platform, recognizing the student when visited and treating them as a valuable visitor. This is a typical feature of a recommendation system since many such systems calculate recommendations based on information obtained from the user’s previous interactions (e.g., ratings given to products). As a result, the more the user interacts with the application, the more refined their model becomes.
Some motivations and advantages for why service providers would want to introduce recommendation systems have been mentioned earlier. Additionally, users may desire such a system if it efficiently supports their tasks or goals. Therefore, a recommendation system must balance the needs of these two players by offering valuable services to both parties (teachers – students). Herlocker (Herlocker et al., 2004), in a work that has become a classic reference in this field, defines eleven tasks that a recommendation system could implement, and which the EDSense platform has taken into account:
- Find some good items: Recommend to a user, in the form of a ranking, certain articles along with the anticipation (e.g., on a scale from one to five) of the user’s preferences. This is the main task of a recommendation system found in most educational systems;
- Find all good items: Recommend all articles that can satisfy user needs. This is especially valid when the number of articles is relatively small or when the recommendation system is of critical importance (e.g., in medical or financial applications);
- Annotations in context: Given a specific context (e.g., a list of articles), mark certain articles based on the user’s long-term preferences. For example, a recommendation system for a certain knowledge item will display only those shows from the existing list that are the most compatible with the user;
- Recommend a sequence: Instead of focusing on generating a single recommendation, the focus is on recommending a series of articles that are enjoyable as a whole. Typical examples include recommending a lesson to learn, a problem to solve, or a personalized quiz;
- Recommend a bundle: Suggest a group of articles that go well together. For example, learning about a single concept can consist of various other concepts related to the core one. From the user’s perspective, these various options can be considered as a single knowledge journey;
- Just browsing: In this type of task, the user browses the manuals without an imminent intention to solve some problems or learn. The task of the recommendation system is to help the user view only articles that are more likely to fit within their area of interest for that browsing session;
- Find credible recommender: Some users do not trust recommendation systems, so they “play” with them to observe the quality of recommendations. In this regard, many recommendation systems offer certain special functions, different from those required to obtain recommendations, to allow users to test their behaviour;
- Improve the profile: This feature refers to the user’s ability to provide the recommendation system with information about their preferences. This is a fundamental task that is strictly necessary to provide personalized recommendations. If the system has no knowledge about the current user, then the recommendations provided to them will be the same as those provided to an “average” user;
- Express self: Some users are not interested at all in receiving recommendations. What matters most to them is the ability to contribute with ratings and express their opinions or beliefs. This task provides satisfaction to users and, as mentioned earlier in the description of service providers’ motivations, acts as a lever to maintain a strong connection with the application;
- Help others: Some users are happy to contribute information (e.g., ratings for certain knowledge articles) because they believe that communities benefit from this information. This could be a motivation for entering information into a recommendation system that is not frequently used. For example, in an educational recommendation system, a user who has solved a problem is aware that the rating entered into the system is much more likely to be useful for other users;
- Influence others: In online recommendation systems, there are certain users whose primary goal is to explicitly influence others in order to purchase specific products. There are also so-called malware users who may use the system only to promote or “penalize” certain articles.
Smart Component III, the “User Comment Analysis Module for Continuous Improvement of Educational Content Using Sentiment Analysis Techniques,” is used within the EDSense platform to gauge the attitudes of platform users (students) towards the available educational content. Interest in natural language processing (NLP) and, consequently, the extraction of opinions from often subjective text has notably increased. Sentiment analysis has been the subject of research for a long time, as seen in the works of Das and Chen (Das & Chen, 2007) and Tong (Zhao et al., 2012), particularly concerning opinions expressed in the educational. It is important to note that sentiment can be classified in terms of positivity at various levels, such as document, sentence, or feature, involving words that express emotions (e.g., angry, sad, happy). For instance, in the context of user comments analysis (Drus & Khalid, 2019), words could be classified into positive and negative categories. Furthermore, some approaches consider a neutral class (with a value of 0) and assign values to words on a scale from -5 to +5. In this case, the scale has been reduced from -3 to +3, considered sufficiently fine for public discourse (Li et al., 2019), and even further, from -1 to +1. In general terms, sentiment analysis involves extracting opinions from text. It also encompasses subjective analysis, as seen in Dave (Dave et al., 2003), where sentiment analysis involves “processing search results for a specific item, generating a list of product attributes (quality, features, etc.), and aggregating opinions for each of them (poor, mixed, good).” Furthermore, sentiment analysis includes various types of analysis and evaluation. Moving beyond subjectivity, sentiment analysis has also focused on objectivity in text, resulting in the classification of texts into two main categories: objective and subjective. This classification is often more challenging than polarity classification (Mihalcea & Tarau, 2004). Today, there is a vast amount of “sentiment” available in social media, including Twitter, Facebook, forums, blogs, etc. Sentiment analysis provides organizations with the ability to monitor opinions about their products/ services and reputation (referred to as feedback) from various social media platforms in real-time and take actions accordingly. The initial classification of analysed texts (sentences/ phrases) may take into account the criterion of subjectivity, resulting in two main classes: objective, containing concrete information, and subjective, containing explicit opinions, beliefs, and views about specific entities. Notable authors with significant contributions and comments on sentiment analysis include (Kenyon-Dean et al., 2018; B. Liu, 2012; Narayanan et al., 2009; Shelar & Huang, 2018; Taboada, 2016; Zhao et al., 2012).
Document-level sentiment analysis is the simplest form of sentiment analysis, assuming that a document contains an opinion about a single main object expressed by the author of the message. In the literature, two approaches to document-level sentiment analysis are found: supervised and unsupervised. The supervised approach involves having a finite set of classes, and documents need to be classified, with training data assigned to each class. The simplest case involves two classes: positive and negative. Additionally, a neutral class can be added, or a numerical scale can be considered for document classification (e.g., SentiWordNet3 (Kardinata et al., 2021)). Using the training data, the system learns a classification model, typically employing classification algorithms like Support Vector Machines (SVM) or K-nearest neighbours (KNN). This classification is then used to label new documents into their respective sentiment classes. Authors like (Khanal, 2010) have shown that good accuracy can be achieved even when representing each document as a “bag of words.” More advanced representations involve considering parts of speech (POS), sentiment lexicons, and parsing structures at the lexical unit level. The unsupervised approach to document-level sentiment analysis relies on determining the Semantic Orientation (SO) of specific phrases within the document. If the average SO of these phrases exceeds a predefined threshold, the document is classified as positive; otherwise, it is considered negative. There are two main approaches for selecting phrases: a set of predefined POS models can be used to select these phrases (Turney, 2008), or a lexicon of sentiment words and expressions can be utilized (Taboada, 2016).
Sentence/ phrase-level sentiment analysis (specific to EDSense development): A single document can contain multiple opinions, even about the same entity. When we want a clearer picture of opinions expressed about an entity (object, being, organization, location, etc.), we need to analyse at the sentence/ phrase level. The initial assumption is that we have knowledge of the identity of the entity mentioned in the text. Furthermore, we assume that each sentence contains only one opinion. This assumption can be achieved by breaking down the sentence into propositions (a text fragment containing a predicative verb), where each proposition contains only one opinion. Before analysing the polarity at the sentence level, we need to determine whether the sentences are subjective or objective. Only subjective sentences will be further analysed. Most methods use supervised techniques to classify sentences into two classes (Hatzivassiloglou & McKeown, 1997). The main premise is that neighbouring sentences should have the same subjective classification. These sentences can then be classified into positive or negative classes. It has also been shown that it is advisable to adopt different strategies for this type of analysis (Narayanan et al., 2009). At a semantic level, challenges can arise from questions, sarcasm, metaphor, humour, elements that are difficult to detect, especially in certain contexts (e.g., political contexts). The aforementioned approaches work well when either the entire document or each analysed text fragment refers to a single entity. However, in many cases, people talk about entities with multiple attributes, and of course, opinions vary. This often occurs in comments about products, services, etc., or in discussion forums dedicated to various categories of entities (such as political figures, cars, cameras, smartphones, and even pharmaceutical products). Emotion-based analysis is a research problem that focuses on recognizing all forms of sentiment expressions in a given document and the aspects they refer to. The classical approach, increasingly used by the public relations departments of large companies/ commercial organizations, involves identifying the emotional nature of comments regarding product quality, services, brand image, etc. In natural language, this entails extracting all nominal structures (NPs) and then retaining only those whose frequency exceeds an experimentally learned threshold (Pooja & Bhalla, 2022). Emotion-based analysis also focuses on recognizing all forms of sentiment expressions in a given document and the entities they refer to. In other words, it identifies evaluative aspects mentioned explicitly in sentences. However, there are many opinions that are not explicitly mentioned in sentences and must be deduced from implicitly mentioned sentiment expressions.
Smart Component IV, the ‘Automatic Generation of Personalized Questionnaires (smart quizzes) according to user profile’ starts from the assumption that assessments that require students to pause and test do not thoroughly assess their comprehension of a subject. On the other hand, assessments utilizing artificial intelligence offer continuous feedback to educators, learners, and parents. This feedback sheds light on the student’s learning approach, identifies areas where assistance may be required, and tracks their advancement in achieving their educational objectives. Over the course of many years, extensive research has consistently demonstrated that the evaluation of knowledge and comprehension cannot be effectively conducted solely through a sequence of 90-minute exams. The predominant approach to exams is fraught with anxiety, unenjoyable experiences, potentially deterring students from pursuing education, and necessitates the diversion of valuable time away from the pursuit of knowledge for both learners and educators. Despite the global recognition that these tools are crude, we continue to depend on them, pushing students into universities and jobs without adequately preparing them for what lies ahead. It is possible that one of the factors contributing to the enduring prevalence of traditional assessment methods, such as standardized tests, is the lack of appealing alternatives. Moreover, these alternatives have proven to be just as, if not more, unpredictable and unreliable than current examination systems. To illustrate this point, let us consider how marks attained through coursework in the school education system have been incorporated into students’ overall exam grades. Concerns regarding the extent to which students are solely responsible for their coursework have resulted in a decline in the appeal of this option, prompting a return to traditional examinations. Within higher education, the implementation of “open book exams” has aimed to alleviate the burden on students to memorize copious amounts of information. While this approach may provide some relief, it merely addresses a fraction of the larger issue at hand, namely the strain placed on memory. There are still other aspects that cause stress and cannot be relied upon, including the conditions of the exams, the narrow scope of the assessment, and the reliability of the grading process. Nevertheless, things have changed now and we have a practical and financially appealing option within our reach. We possess the technological capabilities to construct an advanced assessment system, one that is powered by artificial intelligence (AI). However, the question remains whether we are willing to challenge conventional practices and embrace this innovation from a societal and ethical perspective. The use of AI in education has been a topic of study in academia for over three decades. The goal is to create clear and precise forms of educational, psychological, and social knowledge that are often left unspoken. The evidence from current AI systems that evaluate learning and offer tutoring is encouraging, as they have shown to be accurate in their assessments. By providing a deep, fine-grained understanding of when and how learning actually happens, AI serves as a powerful tool to unlock the mysteries of education. To achieve this, AI assessment systems require specific information, such as the curriculum, subject area, and learning activities that individual students are engaged in. Additionally, details about the steps taken by each student during these activities are crucial. Lastly, AI systems must take into account what defines success within each activity and step towards completion. By applying techniques like computer modelling and machine learning to this data, the AI assessment system can accurately evaluate a student’s knowledge in the studied subject area. AI assessment systems have the capability to evaluate various skills of students, including collaboration and persistence, as well as their personal characteristics such as confidence and motivation. The AI system collects and processes information over a significant duration to form an assessment of each student’s progress. Unlike a brief 90-minute exam, this duration can span an entire school semester, a year, or even multiple years. The output generated by the AI software offers valuable data that can be synthesized and interpreted to create visual representations. The visualizations, known as Open Learner Models (OLMs), serve as representations of a student’s knowledge, skills, or resource needs. These models assist both teachers and students in comprehending their performance and its evaluation. To illustrate, an AI assessment system gathers information regarding a student’s accomplishments, emotional state, and motivation. By analysing this data, an OLM can be created with the aim of: (1) aiding teachers in understanding their students’ learning approaches so they can tailor their future instruction accordingly; and (2) empowering students to monitor their own progress and encourage introspection on their learning journey. AIAssess (Box 1) serves as a universal AI evaluation system that represents merely one method of gauging a student’s knowledge and comprehension. This system is apt for disciplines like mathematics or science and draws from preexisting research instruments. Nonetheless, an assortment of AI methodologies, including natural language processing, speech recognition, and semantic analysis, can be employed to assess student learning effectively. For subjects such as spoken language or history, as well as skills like collaborative problem-solving, a fitting combination of tools would be necessary.
Smart Component V, the ‘User-to-User Q&A Communication System,’ extends the functionality of the EDSense platform by providing users with an interactive environment/ context to enhance their engagement with the platform and the overall knowledge dissemination process. With this component, users will be able to: a) Write various comments associated with different knowledge elements (articles) presented within the DSPs (Digital Study Plans); b) Submit requests for assistance on various knowledge topics; c) Send personalized messages to other users. User-to-user communication must adhere to the strictest security rules, giving users the ability to report any inappropriate content transmitted through the platform. Therefore, it is necessary to define a spam filter to analyse various characteristics of text messages through which they are classified as spam or legitimate. Developing such functionality involves various approaches, including textual analysis using machine learning techniques or the analysis of specific text features typical of spam messages (e.g., forged headers, time of delivery), all requiring frequent updates due to constant attempts by spammers to evade detection by altering the representation of keywords (intentional misspellings or using visually similar characters with different meanings – e.g., 0-o, i-l, rn-m, etc.) and inserting text content that appears legitimate to machine learning-based classification methods (Amayri & Bouguila, 2010; Awad, 2011). In recent years, many issues, including spam detection and classification, have been addressed using artificial intelligence. Classification is the process of making a decision based on examples of correct decisions; thus, it is a supervised learning technique because it requires a pre-classified dataset. During the training process on this dataset, it becomes clear which property of the data indicates membership in a particular class, and this information is saved in a model that will be used for classifying new data. The text classification implemented within this component involves associating a text with a predefined text category. Each word in the document is considered an attribute of the document, creating a vector of attributes containing the words from the text. To improve the classification process, certain frequently occurring words in a vocabulary (e.g., “and,” “the,” “of,” “a”) can be removed, or words can be grouped into 2–3-word groups called n-grams. Several algorithms have been developed to solve this classification problem (Bhowmick & Hazarika, 2018), including Naive Bayes, decision trees, neural networks, logistic regression, and more. Among these, the most commonly used algorithm for text classification is Naive Bayes (Metsis et al., 2006). Naive Bayes is a probabilistic classification algorithm, and its decisions are based on probabilities derived from the preclassified dataset. Additionally, the ‘smart’ attribute associated with the communication system comes from the fact that this system will be able to identify users with the most suitable skills for resolving help requests. These users will receive specific notifications related to the request made, and their identification will be based on recommendation algorithms, as described earlier.
4. Conclusions
As an AI-powered learning platform, EDSense was emphasized in the current paper as a significant step forward in educational technology. By integrating advanced algorithms, it created a personalized and adaptive learning environment, with a high potential for widespread educational impact through its ability to target a diverse range of learners, from primary school students to adults in Romania. The platform’s unique approach to understanding and addressing the varied learning needs of individuals is showcased through its use of sentiment analysis and adaptive recommendation systems. By providing additional learning materials and supporting the official educational curriculum, EDSense offers a comprehensive educational resource for both students and educators. The presented platform is capable to enhance the student engagement and improving learning outcomes through personalized quizzes and learning paths. As EDSense continues to be developed and fine-tuned, it is expected that more advanced features will be introduced, and a deeper understanding of educational requirements will be gained. Also, as AI technology progresses, EDSense can adjust and include new innovations, guaranteeing its relevance and effectiveness in the ever-changing realm of educational technology. Ultimately, the evolution of EDSense from an idea to its realization signifies the revolutionary impact of technology on education, offering a more captivating, individualized, and efficient learning encounter for everyone involved.
* * *
The project “Ed-SENSE – Innovative educational platform for collaborative, collective and individual training, based on an artificial intelligence, gamification and augmented reality system” is financed from European funds through the Regional Operational Program (POR) 2014-2020, Priority Axis 1 – Promoting technology transfer, My SMIS Code: 150022
References
Amayri, O., & Bouguila, N. (2010). A study of spam filtering using support vector machines. Artificial Intelligence Review. https://doi.org/10.1007/s10462-010-9166-x
Awad, W. A. (2011). Machine Learning Methods for Spam E-Mail Classification. International Journal of Computer Science and Information Technology. https://doi.org/10.5121/ijcsit.2011.3112
Bhowmick, A., & Hazarika, S. M. (2018). E-mail spam filtering: A review of techniques and trends. Lecture Notes in Electrical Engineering. https://doi.org/10.1007/978-981-10-4765-7_61
Chiu, T. K. F., Xia, Q., Zhou, X., Chai, C. S., & Cheng, M. (2023). Systematic literature review on opportunities, challenges, and future research recommendations of artificial intelligence in education. In Computers and Education: Artificial Intelligence (Vol. 4). https://doi.org/10.1016/j.caeai.2022.100118
Collins, C., Buhalis, D., & Peters, M. (2003). Enhancing SMTEs’ business performance through the Internet and e-learning platforms. Education + Training, 45. https://doi.org/10.1108/00400910310508874
Das, S. R., & Chen, M. Y. (2007). Yahoo! for amazon: Sentiment extraction from small talk on the Web. Management Science. https://doi.org/10.1287/mnsc.1070.0704
Dave, K., Lawrence, S., & Pennock, D. M. (2003). Mining the peanut gallery: Opinion extraction and semantic classification of product reviews. Proceedings of the 12th International Conference on World Wide Web, WWW 2003. https://doi.org/10.1145/775152.775226
Dogan, M. E., Goru Dogan, T., & Bozkurt, A. (2023). The Use of Artificial Intelligence (AI) in Online Learning and Distance Education Processes: A Systematic Review of Empirical Studies. Applied Sciences (Switzerland), 13(5). https://doi.org/10.3390/app13053056
Drus, Z., & Khalid, H. (2019). Sentiment analysis in social media and its application: Systematic literature review. Procedia Computer Science. https://doi.org/10.1016/j.procs.2019.11.174
Eryılmaz, M., Adabashi, A. M., & Yazıcı, A. (2019). Artificial Intelligence Methods in E-Learning. https://doi.org/10.4018/978-1-5225-8476-6.ch015
Gao, P., Li, J., & Liu, S. (2021). An Introduction to Key Technology in Artificial Intelligence and big Data Driven e-Learning and e-Education. In Mobile Networks and Applications (Vol. 26, Issue 5). https://doi.org/10.1007/s11036-021-01777-7
Gros, B., & García-Peñalvo, F. J. (2016). Future Trends in the Design Strategies and Technological Affordances of E-Learning. In Learning, Design, and Technology. https://doi.org/10.1007/978-3-319-17727-4_67-1
Hatzivassiloglou, V., & McKeown, K. R. (1997). Predicting the semantic orientation of adjectives. https://doi.org/10.3115/976909.979640
Herlocker, J. L., Konstan, J. A., Terveen, L. G., & Riedl, J. T. (2004). Evaluating collaborative filtering recommender systems. In ACM Transactions on Information Systems. https://doi.org/10.1145/963770.963772
Isinkaye, F. O., Folajimi, Y. O., & Ojokoh, B. A. (2015). Recommendation systems: Principles, methods and evaluation. In Egyptian Informatics Journal. https://doi.org/10.1016/j.eij.2015.06.005
Kardinata, E. A., Rakhmawati, N. A., Putra, M. F. P., Najib, A. C., Zuhroh, N. A., Irsyad, A., & Qandi, G. A. (2021). Sentiment Analysis of Indonesia’s National Economic Endurance using Fuzzy Ontology-Based Semantic Knowledge. 3rd 2021 East Indonesia Conference on Computer and Information Technology, EIConCIT 2021. https://doi.org/10.1109/EIConCIT50028.2021.9431895
Kenyon-Dean, K., Ahmed, E., Fujimoto, S., Georges-Filteau, J., Glasz, C., Kaur, B., Lalande, A., Bhanderi, S., Belfer, R., Kanagasabai, N., Sarrazingendron, R., Verma, R., & Ruths, D. (2018). Sentiment analysis: It’s complicated! NAACL HLT 2018 – 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies – Proceedings of the Conference. https://doi.org/10.18653/v1/n18-1171
Khanal, S. (2010). Sentiment Classification using Language Models and Sentence Position Information. Spring.
Li, Z., Fan, Y., Jiang, B., Lei, T., & Liu, W. (2019). A survey on sentiment analysis and opinion mining for social multimedia. Multimedia Tools and Applications. https://doi.org/10.1007/s11042-018-6445-z
Liu, B. (2012). Sentiment analysis and opinion mining. Synthesis Lectures on Human Language Technologies. https://doi.org/10.2200/S00416ED1V01Y201204HLT016
Liu, M., & Yu, D. (2023). Towards intelligent E-learning systems. Education and Information Technologies, 28(7). https://doi.org/10.1007/s10639-022-11479-6
Luan, H., Geczy, P., Lai, H., Gobert, J., Yang, S. J. H., Ogata, H., Baltes, J., Guerra, R., Li, P., & Tsai, C. C. (2020). Challenges and Future Directions of Big Data and Artificial Intelligence in Education. In Frontiers in Psychology (Vol. 11). https://doi.org/10.3389/fpsyg.2020.580820
Metsis, V., Androutsopoulos, I., & Paliouras, G. (2006). Spam filtering with Naive Bayes – Which Naive Bayes? 3rd Conference on Email and Anti-Spam – Proceedings, CEAS 2006.
Mihalcea, R., & Tarau, P. (2004). TextRank: Bringing order into texts. Proceedings of EMNLP.
Montebello, M. (2014). Artificial Intelligence To the Rescue of Elearning. EDULEARN14 Proceedings, July.
Murtaza, M., Ahmed, Y., Shamsi, J. A., Sherwani, F., & Usman, M. (2022). AI-Based Personalized E-Learning Systems: Issues, Challenges, and Solutions. In IEEE Access (Vol. 10). https://doi.org/10.1109/ACCESS.2022.3193938
Narayanan, R., Liu, B., & Choudhary, A. (2009). Sentiment analysis of conditional sentences. EMNLP 2009 – Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: A Meeting of SIGDAT, a Special Interest Group of ACL, Held in Conjunction with ACL-IJCNLP 2009. https://doi.org/10.3115/1699510.1699534
Omar, A., Kalulu, D., & Alijani, G. S. (2011). Management of innovative e-learning environments. Academy of Educational Leadership Journal, 15(3).
Pooja, & Bhalla, R. (2022). A Review Paper on the Role of Sentiment Analysis in Quality Education. In SN Computer Science (Vol. 3, Issue 6). https://doi.org/10.1007/s42979-022-01366-9
Rivera, A. C., Tapia-Leon, M., & Lujan-Mora, S. (2018). Recommendation systems in education: A systematic mapping study. Advances in Intelligent Systems and Computing. https://doi.org/10.1007/978-3-319-73450-7_89
Saleh, E. (2022). Using E-Learning Platform for Enhancing Teaching and Learning in the Field of Social Work at Sultan Qaboos University, Oman. In E-Learning and Digital Education in the Twenty-First Century. https://doi.org/10.5772/intechopen.94301
Shelar, A., & Huang, C. Y. (2018). Sentiment analysis of twitter data. Proceedings – 2018 International Conference on Computational Science and Computational Intelligence, CSCI 2018. https://doi.org/10.1109/CSCI46756.2018.00252
Taboada, M. (2016). Sentiment Analysis: An Overview from Linguistics. In Annual Review of Linguistics. https://doi.org/10.1146/annurev-linguistics-011415-040518
Tang, K. Y., Chang, C. Y., & Hwang, G. J. (2023). Trends in artificial intelligence-supported e-learning: a systematic review and co-citation network analysis (1998–2019). In Interactive Learning Environments (Vol. 31, Issue 4). https://doi.org/10.1080/10494820.2021.1875001
Turney, P. D. (2008). A uniform approach to analogies, synonyms, antonyms, and associations. Coling 2008 – 22nd International Conference on Computational Linguistics, Proceedings of the Conference. https://doi.org/10.3115/1599081.1599195
Zhang, K., & Aslan, A. B. (2021). AI technologies for education: Recent research & future directions. In Computers and Education: Artificial Intelligence (Vol. 2). https://doi.org/10.1016/j.caeai.2021.100025
Zhao, T., Li, C., Ding, Q., & Li, L. (2012). User-Sentiment topic model: Refining user’s topics with sentiment information. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. https://doi.org/10.1145/2350190.2350200
____________________
Authors:
Marius Ivanov
Altfactor
marius.ivanov@altfactor.ro
Dragoș Sebastian Cristea
Altfactor, ”Dunarea de Jos” University of Galati
![]() https://orcid.org/0000-0001-8227-4854
https://orcid.org/0000-0001-8227-4854
Mihai Vlase
Altfactor, ”Dunarea de Jos” University of Galati
![]() https://orcid.org/0009-0008-6806-0380
https://orcid.org/0009-0008-6806-0380
Dan Munteanu
Altfactor
![]() https://orcid.org/0000-0002-9518-2366
https://orcid.org/0000-0002-9518-2366
Received: 20.10.2023. Accepted: 27.11.2023
© Marius Ivanov, Dragoș Sebastian Cristea, Mihai Vlase, Dan Munteanu / Altfactor, 2023. This open access article is distributed under the terms of the Creative Commons Attribution Licence CC BY, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited:
Citation:
Ivanov, M., Cristea, D.S., Vlase, M., Munteanu, D. (2023). Navigating Learning Paths with EDSense: An AI-Powered Learning Platform. Journal of Digital Pedagogy, 2(1) 14-24. Bucharest: Institute for Education. https://doi.org/10.61071/JDP.2375